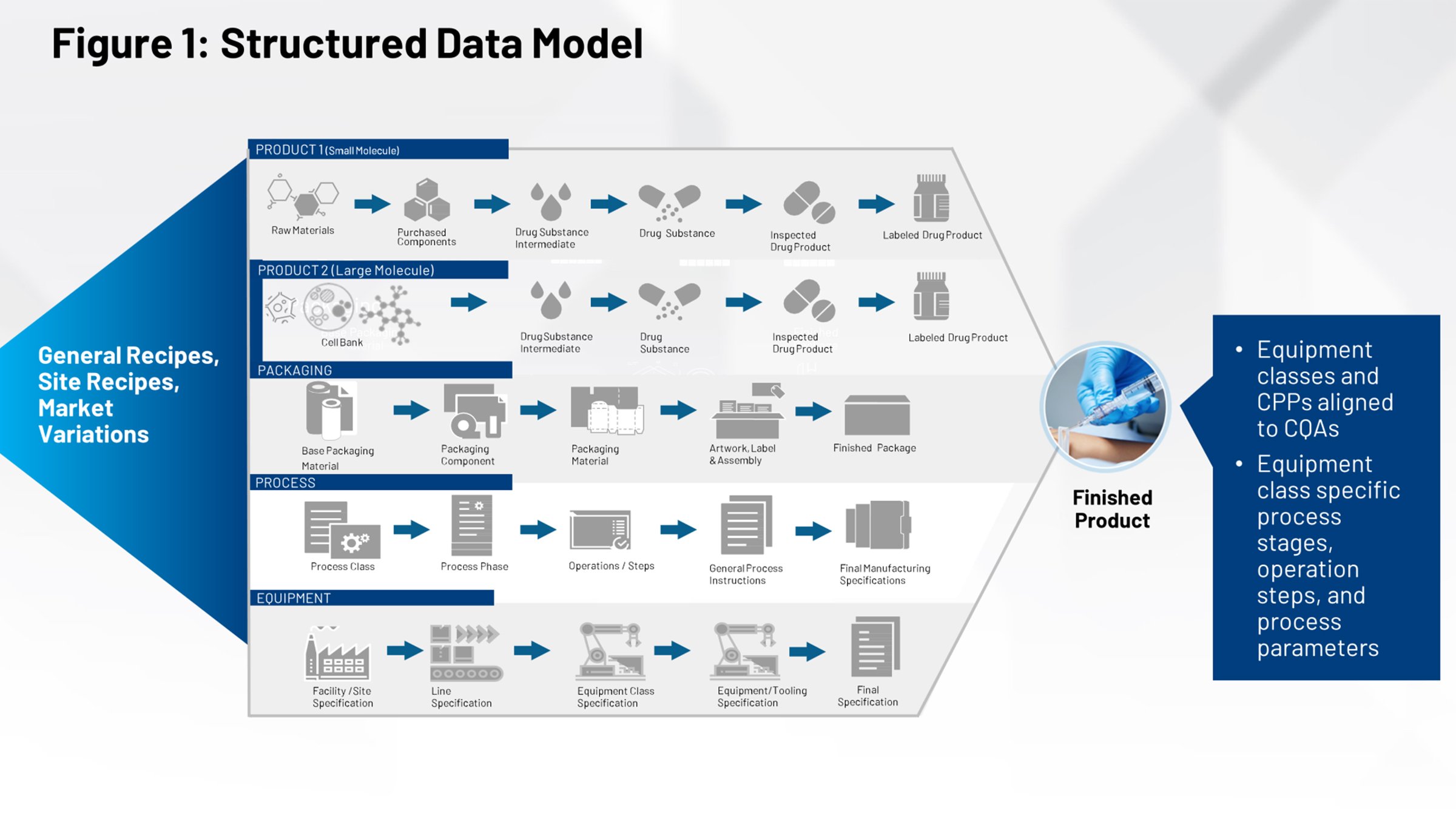
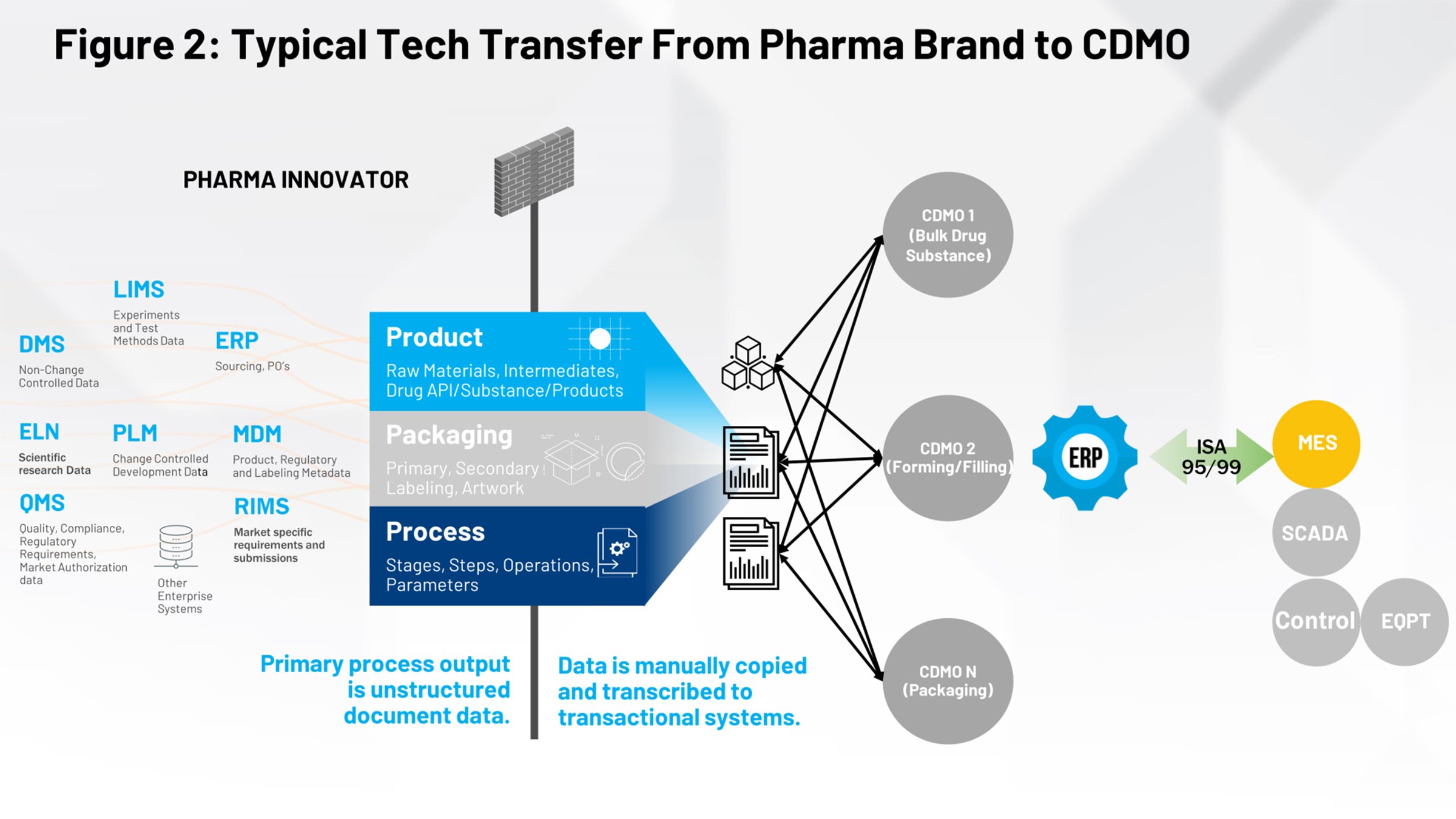
图 2 展示了生命科学行业人员所熟知的当前技术转移过程。图片左侧是在技术转移前用于定义产品、包装和工艺的系统。所有这些技术转移的数据都需要通过防火墙,被内部制造部门或外部的CDMO企业所接收。
我们的任务是将这些电子文档或基于图像的文档转换为结构化且可重复的数字化内容,从而稳定地提供至下方合作伙伴,并消除解释文档内容的人为工作。这样,任何下方合作伙伴均可以安全有效的利用这些技术转移数据。
我们是如何做到的
看看完成这项任务的过程,首先我们需要确保提交的数据是安全的。许多公司通过 FTP、电子邮件、电话和网站进行通信,从控制策略角度来看,这么做很难保护知识产权 (IP)。总之,在技术转移过程中流动的数据很多都是企业的知识产权,必须得到保护并在适当的时间提供给合适的一方。
这不仅仅是数据的转换;还涉及数据跟踪。在发生不良事件时,您需要进行审计跟踪,以便准确了解转换内容、审批人员、签署人员、数据接收人员和数据使用人员。
有人负责收集来自科学家和过程开发工程师使用的不同系统的所有信息。然后,他们需要将信息汇总至单个文档或文档概要中,并编排将数据交付给制造部门的过程。
我们缺少的是像谷歌翻译这样的编排和转换工具,它能够理解您试图通过技术转移进行交流的真正意图,并将其转化为可预测和可利用的东西。
其理念是,一旦将数据解析为可理解、可重复使用的格式,下游接收方就不需要人工输入所有信息。相反,信息会自动推送至需要它的系统。
我们旨在使用自然语言处理机制来理解文档(语境、语义和语法意图),并使用机器学习算法来理解每个文档的意图并将其转换为 ISA 88 结构化格式。本质上而言,它将文档与数字数据拼接在一起,形成系统可以轻松使用的的可重复使用的结构化数据。
但技术转移文档不仅仅只包含表格或层级结构形式的数字或文本数据,还会包含图像数据、色谱分析,以及抽样方法和测试方法。这些非结构化数据集无法轻松转换为数字数据。但它们与某个层级的数字数据相关,因此您需要能够理解文档中可能隐藏在不同数据集之间的内在差异。
当您使用自然语言处理工具运行文档时,它可以拍摄扫描图像并使用光学字符识别 (OCR) 技术提取数据。或者,如果数字数据最初是从一份 PDF 文档中捕获的,那么可以再次提取数据。
某些情况下,数据缺乏上下文背景。工具只是用于提取数据,并表示:“我了解文档中存在的数据量。” 我们可以利用自然语言处理工具的输出功能寻找关键指标,创建更易于被下方接收系统导入或应用的表格数据集。
这种方法的优势之一是能够实现协作。如果没有看懂 PDF 文档上的某个数值,便很难与他人开展协作。如何传达这一点? 您发了一封电子邮件,上面写道,“嘿,在文档第 22 页第 3 段第 4 行有一个数值,我看不懂。” 如果您能够提取这些信息,智能层就可以告诉您缺少什么,或者突出显示您应该注意的部分,从而使流程更加高效。
选择一种途径
有两个方向。一是继续做当前正在做的事情,因为您对其有深入了解。在生命科学行业,推动变革困难重重。因此,您可以继续与开发企业开展合作,让他们继续制作多年一直使用的 PDF 文档,然后使用自然语言处理层将其转换为数字化、可重复使用且易于读取的内容。这是其中一种途径。
第二种途径是采用数字化原生工具,允许您在开发早期阶段对过程和材料进行建模,并发布本地数字数据集。当然我们需要面对现实,因为我们知道,在生命科学行业的某些领域中,需要数年甚至数十年的时间才能采用原生数字解决方案。
在此期间,我们正在推广这两种途径:首先,利用人工智能和机器学习的计算能力,将文档转换为可重复使用的格式,然后再逐渐采用数字化原生工具。这么做的最大优势是提高劳动效率,但还有其他优势:
- 加快临床试验、上市和市场授权的速度
- 降低内外部转移至制造环节的总成本
- 提高工艺验证的速度和效率
- 减少设施、产线和设备配置/启动的延迟
- 提高批次质量,减少废料和浪费
- 提高监管递交和审批的速度
- 从开发、制造至监管流程中,通过设计提高闭环质量
- 改进批次谱系的可追溯性(正确的国家和产品信息)